Here are some collected notes on some particular problems from packaging Python stuff for Debian, and more are coming up like this in the future.
Some of the issues discussed here might be rather simple and even benign for the experienced packager, but maybe this is be helpful for people coming across the same issues for the first time, wondering what's going wrong.
But some of the things discussed aren't easy.
Here are the notes for this posting, there is no particular order.
UnicodeDecoreError on
open() in Python 3 running in non-UTF-8 environments
I've came across this problem again recently packaging
httpbin 0.5.0.
The build breaks the following way e.g. trying to build with sbuild in a chroot,
that's the first run of
setup.py with the default Python 3 interpreter:
I: pybuild base:184: python3.5 setup.py clean
Traceback (most recent call last):
File "setup.py", line 5, in <module>
os.path.join(os.path.dirname(__file__), 'README.rst')).read()
File "/usr/lib/python3.5/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 2386: ordinal not in range(128)
E: pybuild pybuild:274: clean: plugin distutils failed with: exit code=1: python3.5 setup.py clean
One comes across
UnicodeDecodeError-s quite oftenly on different occasions,
mostly related to Python 2 packaging (like
here).
Here it's the case that in
setup.py the
long_description is tried to be read from the opened UTF-8 encoded file
README.rst:
long_description = open(
os.path.join(os.path.dirname(__file__), 'README.rst')).read()
This is a problem for Python 3.5 (and other Python 3 versions) when
setup.py is executed by an interpreter run in a non-UTF-8 environment
:
$ LANG=C.UTF-8 python3.5 setup.py clean
running clean
$ LANG=C python3.5 setup.py clean
Traceback (most recent call last):
File "setup.py", line 5, in <module>
os.path.join(os.path.dirname(__file__), 'README.rst')).read()
File "/usr/lib/python3.5/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 2386: ordinal not in range(128)
$ LANG=C python2.7 setup.py clean
running clean
The reason for this error is, the default encoding for file object returned by
open() e.g. in
Python 3.5 is platform dependent, so that
read() fails on that when there's a mismatch:
>>> readme = open('README.rst')
>>> readme
<_io.TextIOWrapper name='README.rst' mode='r' encoding='ANSI_X3.4-1968'>
Non-UTF-8 build environments because
$LANG isn't particularly set at all or set to
C are common or even default in Debian packaging, like in the continuous integration resp. test building for reproducible builds the primary environment features that (see
here).
That's also true for the base system of the sbuild environment:
$ schroot -d / -c unstable-amd64-sbuild -u root
(unstable-amd64-sbuild)root@varuna:/# locale
LANG=
LANGUAGE=
LC_CTYPE="POSIX"
LC_NUMERIC="POSIX"
LC_TIME="POSIX"
LC_COLLATE="POSIX"
LC_MONETARY="POSIX"
LC_MESSAGES="POSIX"
LC_PAPER="POSIX"
LC_NAME="POSIX"
LC_ADDRESS="POSIX"
LC_TELEPHONE="POSIX"
LC_MEASUREMENT="POSIX"
LC_IDENTIFICATION="POSIX"
LC_ALL=
A problem like this is solved mostly elegant by installing some workaround in
debian/rules.
A quick and easy fix is to add
export LC_ALL=C.UTF-8 here, which supersedes the locale settings of the build environment.
$LC_ALL is commonly used to change the existing locale settings, it overrides all other locale variables with the same value (see
here).
C.UTF-8 is an UTF-8 locale which is available by default in a base system, it could be used without installing the
locales package (or worse, the huge
locales-all package):
(unstable-amd64-sbuild)root@varuna:/# locale -a
C
C.UTF-8
POSIX
This problem ideally should be
taken care of upstream.
In Python 3, the default
open() is
io.open(), for which the specific encoding could be given, so that the
UnicodeDecodeError disappears.
Python 2 uses
os.open() for
open(), which doesn't support that, but has
io.open(), too.
A fix which works for both Python branches goes like this:
import io
long_description = io.open(
os.path.join(os.path.dirname(__file__), 'README.rst'), encoding='utf-8').read()
non-deterministic order of requirements in
egg-info/requires.txt
This problem appeared in
prospector/0.11.7-5 in the reproducible builds test builds, that was the first package of Prospector running on Python 3
.
It was revealed that there were differences in the sorting order of the
[with_everything] dependencies resp. requirements in
prospector-0.11.7.egg-info/requires.txt if the package was build on
varying systems:
$ debbindiff b1/prospector_0.11.7-5_amd64.changes b2/prospector_0.11.7-5_amd64.changes
...
prospector_0.11.7-5_all.deb
file list
@@ -1,3 +1,3 @@
-rw-r--r-- 0 0 0 4 2016-04-01 20:01:56.000000 debian-binary
--rw-r--r-- 0 0 0 4343 2016-04-01 20:01:56.000000 control.tar.gz
+-rw-r--r-- 0 0 0 4344 2016-04-01 20:01:56.000000 control.tar.gz
-rw-r--r-- 0 0 0 74512 2016-04-01 20:01:56.000000 data.tar.xz
control.tar.gz
control.tar
./md5sums
md5sums
Files in package differ
data.tar.xz
data.tar
./usr/share/prospector/prospector-0.11.7.egg-info/requires.txt
@@ -1,12 +1,12 @@
[with_everything]
+pyroma>=1.6,<2.0
frosted>=1.4.1
vulture>=0.6
-pyroma>=1.6,<2.0
Reproducible builds folks recognized this to be a toolchain problem and set up the issue
randonmness_in_python_setuptools_requires.txt to cover this.
Plus, a wishlist
bug against python-setuptools was filed to fix this.
The patch which was provided by Chris Lamb adds sorting of dependencies in
requires.txt for Setuptools by adding
sorted() (stdlib) to
_write_requirements() in
command/egg_info.py:
--- a/setuptools/command/egg_info.py
+++ b/setuptools/command/egg_info.py
@@ -406,7 +406,7 @@ def warn_depends_obsolete(cmd, basename, filename):
def _write_requirements(stream, reqs):
lines = yield_lines(reqs or ())
append_cr = lambda line: line + '\n'
- lines = map(append_cr, lines)
+ lines = map(append_cr, sorted(lines))
stream.writelines(lines)
O.k. In the toolchain, nothing sorts these requirements alphanumerically to make differences disappear, but what is the reason for these differences in the Prospector packages, though?
The problem is somewhat subtle.
In
setup.py,
[with_everything] is a dictionary entry of
_OPTIONAL (which is used for
extras_require) that is created by a list comprehension out of the other values in that dictionary.
The code goes like this:
_OPTIONAL =
'with_frosted': ('frosted>=1.4.1',),
'with_vulture': ('vulture>=0.6',),
'with_pyroma': ('pyroma>=1.6,<2.0',),
'with_pep257': (), # note: this is no longer optional, so this option will be removed in a future release
_OPTIONAL['with_everything'] = [req for req_list in _OPTIONAL.values() for req in req_list]
The result, the new
_OPTIONAL dictionary including the key
with_everything (which w/o further sorting is the source of the list of requirements
requires.txt) e.g. looks like this (code snipped run through in my IPython):
In [3]: _OPTIONAL
Out[3]:
'with_everything': ['vulture>=0.6', 'pyroma>=1.6,<2.0', 'frosted>=1.4.1'],
'with_vulture': ('vulture>=0.6',),
'with_pyroma': ('pyroma>=1.6,<2.0',),
'with_frosted': ('frosted>=1.4.1',),
'with_pep257': ()
That list comprehension iterates over the other dictionary entries to gather the value of
with_everything, and Python programmers know that of course dictionaries are not indexed and therefore the order of the key-value pairs isn't fixed, but is determined by certain conditions.
That's the source for the non-determinism of this Debian package revision of Prospector.
This problem has been fixed
by a patch,
which just presorts the list of requirements before it gets added to
_OPTIONAL:
@@ -76,8 +76,8 @@
'with_pyroma': ('pyroma>=1.6,<2.0',),
'with_pep257': (), # note: this is no longer optional, so this option will be removed in a future release
-_OPTIONAL['with_everything'] = [req for req_list in _OPTIONAL.values() for req in req_list]
-
+with_everything = [req for req_list in _OPTIONAL.values() for req in req_list]
+_OPTIONAL['with_everything'] = sorted(with_everything)
In comparison to the list method
sort(), the function
sorted() does not change iterables in-place, but returns a new object.
Both could be used.
As a side note,
egg-info/requires.txt isn't even needed, but that's another issue.
 Welcome to gambaru.de. Here is my monthly report that covers what I have been doing for Debian. If you re interested in Java, Games and LTS topics, this might be interesting for you.
Debian Games
Welcome to gambaru.de. Here is my monthly report that covers what I have been doing for Debian. If you re interested in Java, Games and LTS topics, this might be interesting for you.
Debian Games

 My monthly report covers a large part of what I have been doing in the free software world. I write it for
My monthly report covers a large part of what I have been doing in the free software world. I write it for  Stardicter 0.11,
Stardicter 0.11,  I continue to be a big user of Perl, and for many of my sites I avoid
the use of MySQL which means that I largely store data in flat files,
SQLite databases, or in memory via
I continue to be a big user of Perl, and for many of my sites I avoid
the use of MySQL which means that I largely store data in flat files,
SQLite databases, or in memory via 
 They first thing I d like to call eBay on is a statement in their webpage about
They first thing I d like to call eBay on is a statement in their webpage about



 we're not running out of (perl-related) RC bugs. here's my list for this
week:
we're not running out of (perl-related) RC bugs. here's my list for this
week:
 I just published the videos from
I just published the videos from 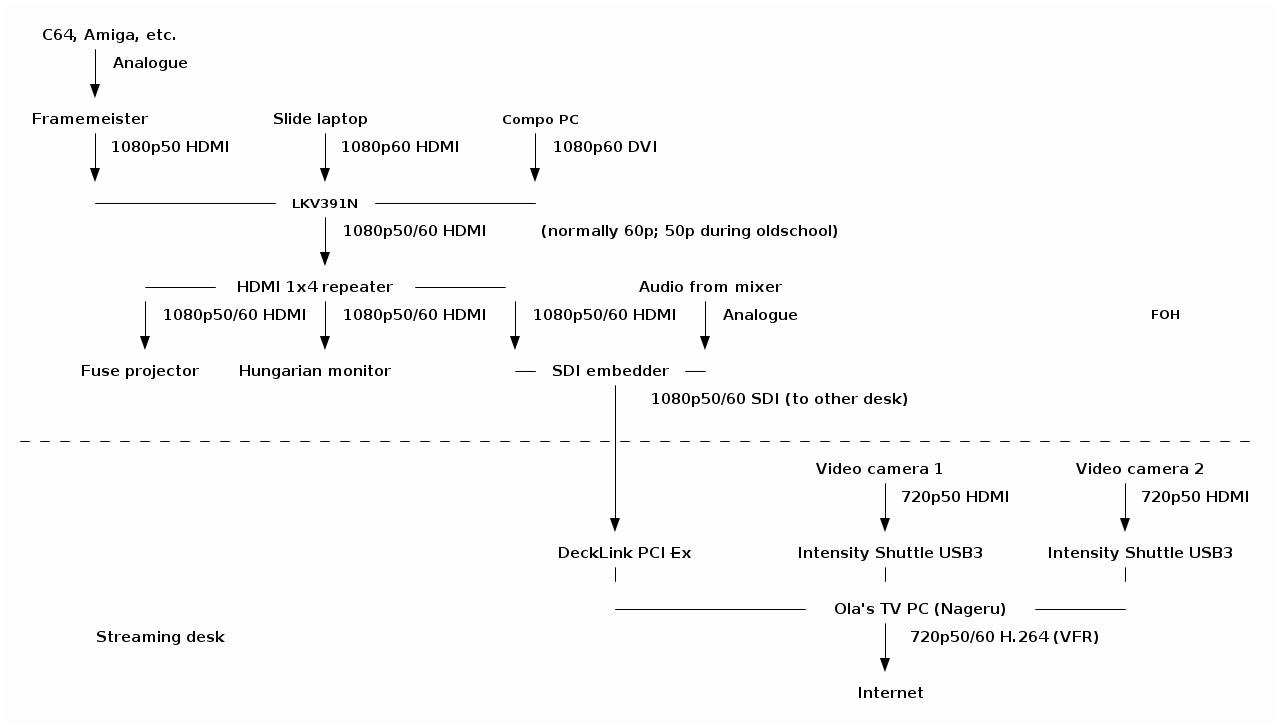 Of course, for me, the really interesting part here is near the end of the
chain, with
Of course, for me, the really interesting part here is near the end of the
chain, with 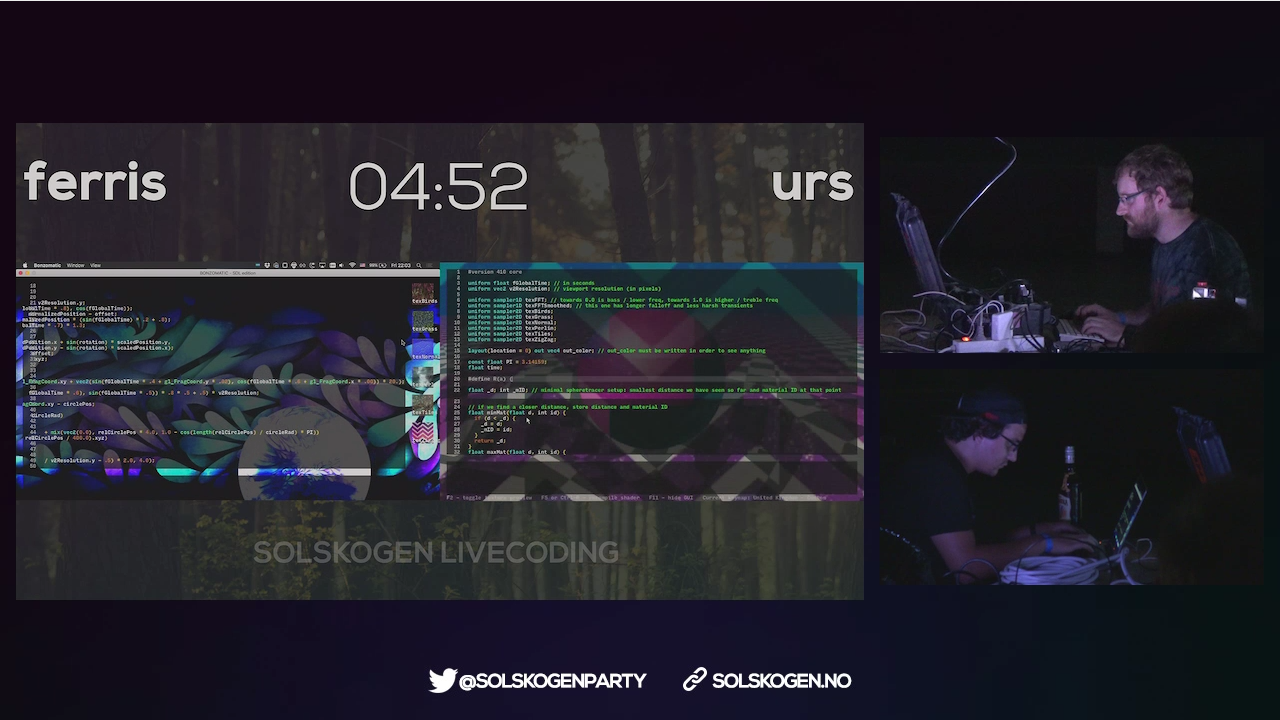 (Unfortunately, I forgot to take a screenshot of Nageru itself during this
run.)
Solskogen was the first time I'd really used Nageru in production, and
despite super-extensive testing, there's always something that can go wrong.
And indeed there was: First of all, we discovered that the local Internet
line was reduced from 30/10 to 5/0.5 (which is, frankly, unusable for
streaming video), and after we'd half-way fixed that (we got it to
25/4 or so by prodding the ISP, of which we could reserve about 2 for
video demoscene content is really hard to encode, so I'd prefer a lot
more) Nageru started crashing.
It wasn't even crashes I understood anything of. Generally it seemed like the
NVIDIA drivers were returning GL_OUT_OF_MEMORY on things like creating
mipmaps; it's logical that they'd be allocating memory, but we had 6 GB of
GPU memory and 16 GB of CPU memory, and lots of it was free. (The PC we used for encoding was much,
much faster than what you need to run Nageru smoothly, so we had plenty of
CPU power left to run x264 in, although you can of course always want more.)
It seemed to be mostly related to zoom transitions, so I generally avoided
those and ran that night's compos in a more static fashion.
It wasn't until later that night (or morning, if you will) that I actually
understood the bug (through the godsend of the
(Unfortunately, I forgot to take a screenshot of Nageru itself during this
run.)
Solskogen was the first time I'd really used Nageru in production, and
despite super-extensive testing, there's always something that can go wrong.
And indeed there was: First of all, we discovered that the local Internet
line was reduced from 30/10 to 5/0.5 (which is, frankly, unusable for
streaming video), and after we'd half-way fixed that (we got it to
25/4 or so by prodding the ISP, of which we could reserve about 2 for
video demoscene content is really hard to encode, so I'd prefer a lot
more) Nageru started crashing.
It wasn't even crashes I understood anything of. Generally it seemed like the
NVIDIA drivers were returning GL_OUT_OF_MEMORY on things like creating
mipmaps; it's logical that they'd be allocating memory, but we had 6 GB of
GPU memory and 16 GB of CPU memory, and lots of it was free. (The PC we used for encoding was much,
much faster than what you need to run Nageru smoothly, so we had plenty of
CPU power left to run x264 in, although you can of course always want more.)
It seemed to be mostly related to zoom transitions, so I generally avoided
those and ran that night's compos in a more static fashion.
It wasn't until later that night (or morning, if you will) that I actually
understood the bug (through the godsend of the

 I bought some
I bought some